Check this Colab Notebook for a short and sweet demo.
What is a slowly changing dimension?
Slowly changing dimensions are a dimensional modelling technique created for historising changes in data.
This technique only works if the dimensions change slower than we read the data, since we would not be able to track changes happening between reads. For example, if someone changes their address once in a blue moon, we will capture the changes with daily loads - but if they change their address 3x in a day, we will only see the last state and only capture 2 of the 4 versions of the address.
However, they enable you to track things you could not before such as
- Hard deletes
- Most of the changes and when they occurred
- Different versions of entities valid at different historical times
What is Slowly Changing Dimension Type 2 (SCD2)? and why use it?
The Type 2 subtype of Slowly Changing Dimensions (SCD) manages changes in data over time. When data changes, a new record is added to the database, but the old record remains unchanged. Each record includes a timestamp or version number. This allows you to view both the historical data and the most current data separately.
Traditional data loading methods often involve updating existing records with new information, which results in the loss of historical data.
SCD2 not only preserves an audit trail of data changes but also allows for accurate historical analysis and reporting.
SCD2 applications
Use Case 1: Versioning a record that changes
In environments where maintaining a complete historical record of data changes is crucial, such as in financial services or healthcare, SCD Type 2 plays a vital role. For instance, if a customer's address changes, SCD2 ensures that the old address is preserved in historical records while the new address is available for current transactions. This ability to view the evolution of data over time supports auditing, tracking changes, and analyzing trends without losing the context of past information. It allows organizations to track the lifecycle of a data entity across different states.
Here's an example with the customer address change.
Before:
_dlt_valid_from | _dlt_valid_to | customer_key | c1 | c2 |
|---|---|---|---|---|
| 2024-04-09 18:27:53.734235 | NULL | 1 | 123 Elm St | TN |
After update:
_dlt_valid_from | _dlt_valid_to | customer_key | c1 | c2 |
|---|---|---|---|---|
| 2024-04-09 18:27:53.734235 | 2024-05-01 17:00:00.000000 | 1 | 123 Elm St | TN |
| 2024-05-02 08:00:00.000000 | NULL | 1 | 456 Oak Ave | TN |
In the updated state, the previous address record is closed with an _dlt_valid_to timestamp, and a new record is created
with the new address "456 Oak Ave" effective from May 2, 2024. The NULL in the _dlt_valid_to field for this
new record signifies that it is the current and active address.
Use Case 2: Tracking deletions
This approach ensures that historical data is preserved for audit and compliance purposes, even though the record is no longer active in the current dataset. It allows businesses to maintain integrity and a full historical trail of their data changes.
State Before Deletion: Customer Record Active
_dlt_valid_from | _dlt_valid_to | customer_key | c1 | c2 |
|---|---|---|---|---|
| 2024-04-09 18:27:53.734235 | NULL | 1 | 123 Elm St | TN |
This table shows the customer record when it was active, with an address at "123 Elm St". The _dlt_valid_to field is NULL, indicating that the record is currently active.
State after deletion: Customer record marked as deleted
_dlt_valid_from | _dlt_valid_to | customer_key | c1 | c2 |
|---|---|---|---|---|
| 2024-04-09 18:27:53.734235 | 2024-06-01 10:00:00.000000 | 1 | 123 Elm St | TN |
In this updated table, the record that was previously active is marked as deleted by updating the _dlt_valid_to field
to reflect the timestamp when the deletion was recognized, in this case, June 1, 2024, at 10:00 AM. The presence
of a non-NULL _dlt_valid_to date indicates that this record is no longer active as of that timestamp.
Learn how to customise your column names and validity dates in our SDC2 docs.
Surrogate keys, what are they? Why use?
Every record in the SCD2 table needs its own id. We call this a surrogate key. We use it to identify the specific record or version of an entity, and we can use it when joining to our fact tables for performance (as opposed to joining on entity id + validity time).
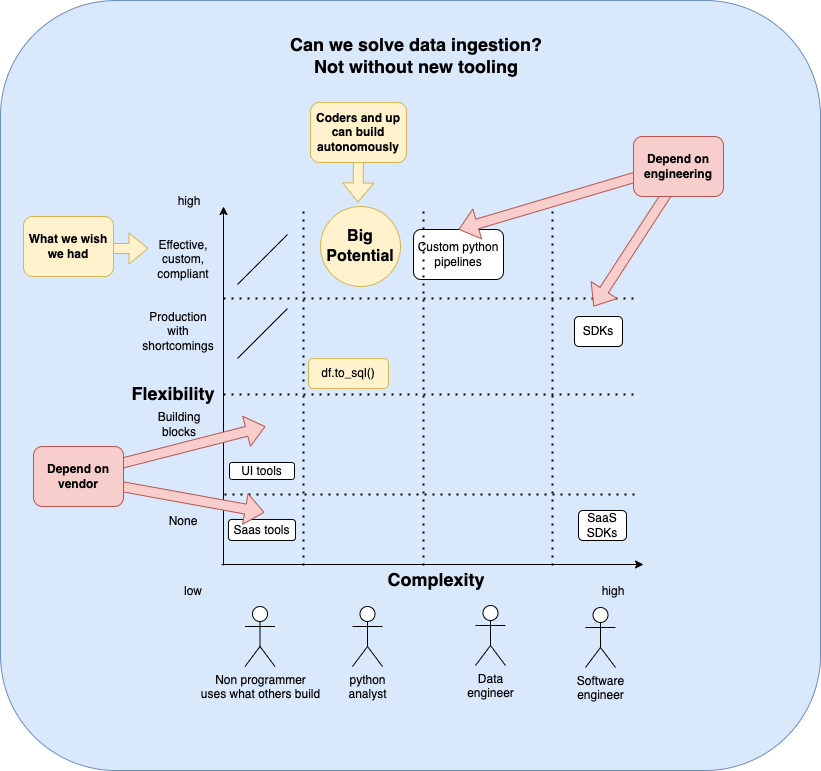
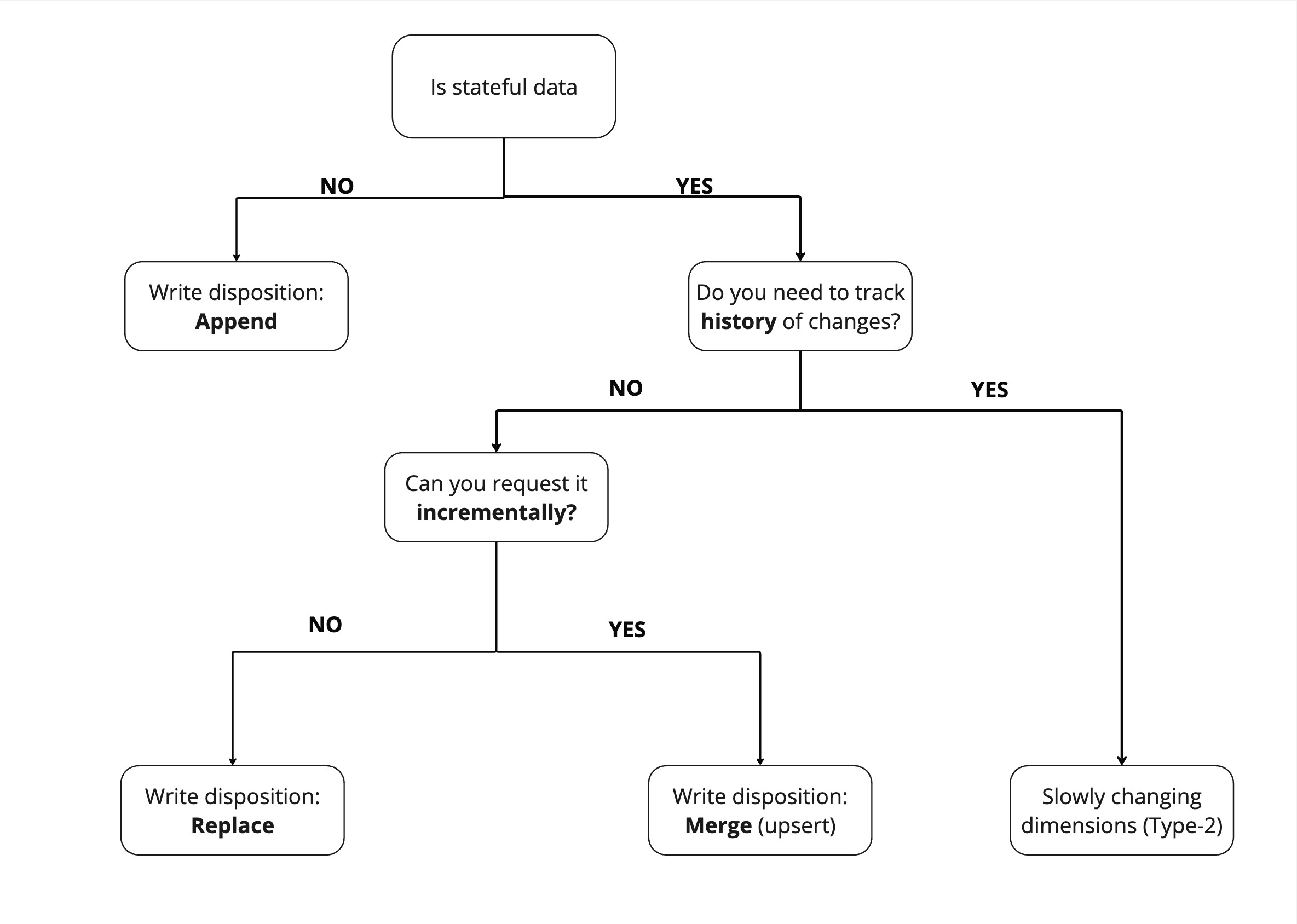
Simple steps to determine data loading strategy and write disposition
This decision flowchart helps determine the most suitable data loading strategy and write disposition:
Is your data stateful? Stateful data is subject to change, like your age. Stateless data does not change, for example, events that happened in the past are stateless.
- If your data is stateless, such as logs, you can just increment by appending new logs.
- If it is stateful, do you need to track changes to it?
- If yes, then use SCD2 to track changes.
- If no,
- Can you extract it incrementally (new changes only)?
- If yes, load incrementally via merge.
- If no, re-load fully via replace.
- Can you extract it incrementally (new changes only)?
Below is a visual representation of steps discussed above:
Conclusion
Use SCD2 where it makes sense but keep in mind the shortcomings related to the read vs update frequency. Use dlt to do it at loading and keep everything downstream clean and simple.
Want to discuss? Join the dlt slack community!